GPT-4 and other large language models (LLMs) have become very popular because of their capacity to produce content that is both contextually relevant and coherent when given a straightforward cue. Generative AI, which encompasses machine learning systems intended to produce original material, is the more general term for these models. In contrast to more straightforward models that forecast using pre-established data, LLMs are highly effective at producing intricate, human-like replies, which makes them a vital tool for a variety of applications, including content production and customer service.
Training Large Language Models
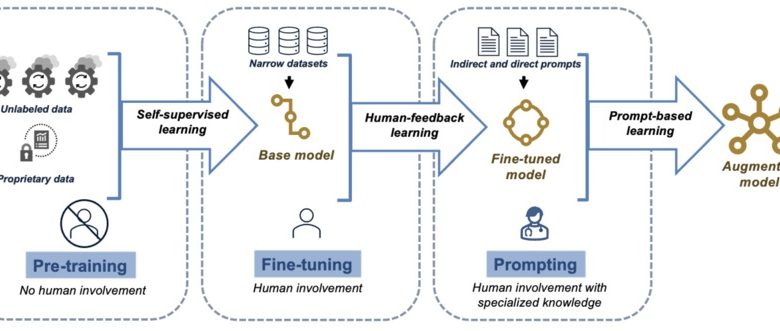
Large volumes of textual data, frequently collected from a wide range of online sources, are the first step in training a large language model. The model gains the ability to anticipate the following word in a sentence by using the words it has already seen during training. The model may make erroneous predictions at first, but with continued training, it begins to identify patterns and contextual signals that enable it to produce intelligible phrases. This method is called “unsupervised learning,” in which the model picks up knowledge straight from unprocessed data without any direct human assistance.
The Transformer Architecture
It is the transformer architecture that makes LLMs effective. Transformers are a kind of neural network that, unlike earlier models, analyses input data simultaneously instead of sequentially. This key difference is what makes LLMs distinct from other types of machine learning models, such as generative AI models used for tasks like image creation. LLM vs Generative AI typically refers to the different areas these models are specialized in, with LLMs focusing on text generation and generative AI being broader, encompassing image, music, and code generation. LLMs are extremely effective at learning from huge datasets because of this architecture, which allows them to process big volumes of text at once. LLMs like GPT-4 are able to produce a wide range of sophisticated text outputs because transformers are able to capture the subtleties of language by examining the links between words, phrases, and sentences.
Generating Text with LLMs
After training, LLMs create text in response to particular inputs by using the patterns they have learnt. For instance, when a user enters a prompt like “Write a letter to a friend about your recent vacation,” the model uses what it has learned to generate a letter that is relevant to the context and makes sense. Additionally, the model may modify its structure, tone, and style in response to additional instructions, making it adaptable to a range of activities, from technical writing to informal discussions.
Conclusion
LLMs like GPT-4 advance AI by producing context-aware, relevant text. Transformer architecture processes enormous information to train them to recognize complex linguistic patterns. When integrated into customer service systems, LLMs can boost productivity by answering consumer questions quickly and accurately. AI’s ability to improve consumer relations in various businesses may improve as technology advances.